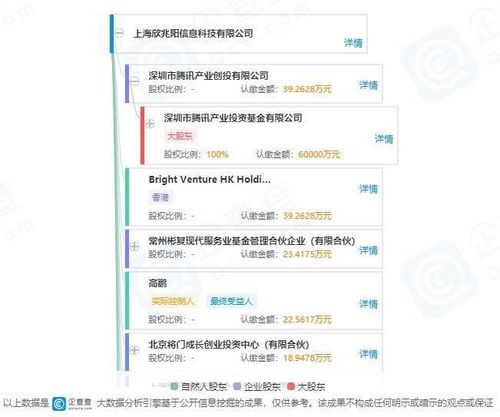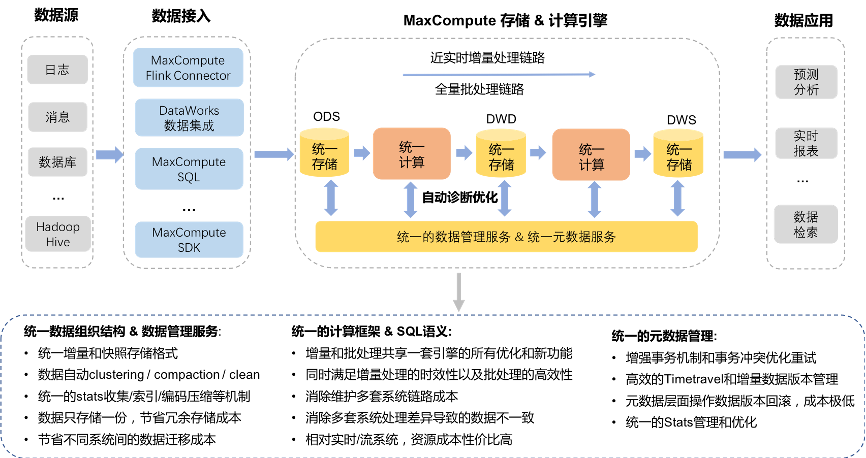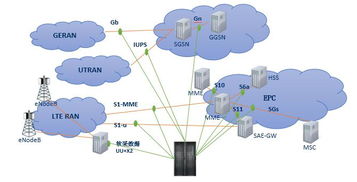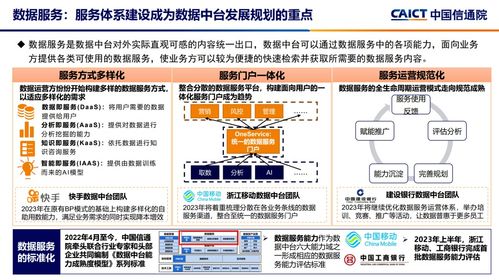
隨著數據量的爆炸式增長和人工智能技術的深度融合,2023年大數據領域展現(xiàn)出前所未有的活力與變革。數據處理與存儲支持服務作為整個大數據生態(tài)的基石,其技術演進與市場動態(tài)成為行業(yè)發(fā)展的核心驅動力。以下是2023年大數據領域的十大關鍵詞,它們深刻描繪了數據處理與存儲支持服務的最新趨勢與未來方向。
- 湖倉一體(Lakehouse): 湖倉一體架構在2023年走向成熟,成為企業(yè)數據平臺建設的主流選擇。它融合了數據湖的靈活性與數據倉庫的高性能治理,通過統(tǒng)一的元數據層、事務支持和多樣化工作負載引擎,實現(xiàn)了數據在存儲層面的“存算分離”與邏輯層面的“統(tǒng)一治理”,極大地簡化了從原始數據到分析洞察的管道。
- 實時數據湖: 傳統(tǒng)批處理數據湖正向實時化演進。借助Apache Iceberg、Hudi和Delta Lake等開源表格式的普及,結合Flink、Spark Streaming等流處理引擎,企業(yè)能夠構建支持低延遲更新、增量處理和實時分析的數據湖,滿足風控、推薦、物聯(lián)網等場景對數據時效性的苛刻要求。
- 存算分離與對象存儲: 為追求極致的彈性、成本效益和可擴展性,存算分離架構成為云上大數據平臺的標配。對象存儲(如AWS S3、阿里云OSS)憑借其近乎無限的擴展能力和低廉的成本,成為海量冷溫數據的主要歸宿,而計算資源則可根據需求動態(tài)伸縮,兩者通過高速網絡和緩存技術高效協(xié)同。
- 數據編織(Data Fabric): 面對跨云、混合云以及邊緣環(huán)境下的數據孤島,數據編織作為一種架構和方法論備受關注。它通過智能化的元數據驅動、知識圖譜和主動數據治理,實現(xiàn)數據的自動發(fā)現(xiàn)、集成、治理和可信交付,為上層應用提供統(tǒng)一、安全的數據訪問層,降低數據整合的復雜性。
- 向量數據庫與AI原生數據棧: 大語言模型(LLM)和生成式AI的爆發(fā),催生了向量數據庫的興起。這類數據庫專為高效存儲、檢索高維向量(嵌入)而設計,是構建AI應用(如語義搜索、個性化推薦、智能問答)的關鍵基礎設施。數據處理與存儲服務正加速與AI工作流集成,形成“AI原生”的數據棧。
- Serverless數據處理: 無服務器(Serverless)模式從計算延伸到數據處理全鏈路。用戶無需管理底層服務器,只需按實際使用的處理量和存儲量付費。云廠商提供的Serverless化數據服務(如AWS Athena、Google BigQuery、阿里云MaxCompute)大幅降低了大數據技術的使用門檻和運維負擔,讓企業(yè)更專注于業(yè)務邏輯。
- 數據治理與隱私計算: 在數據安全法和隱私保護法規(guī)日趨嚴格的背景下,主動式、智能化的數據治理平臺成為剛需。隱私計算技術(如聯(lián)邦學習、安全多方計算、可信執(zhí)行環(huán)境)實現(xiàn)在數據“可用不可見”的前提下進行聯(lián)合分析,成為跨組織數據價值挖掘的重要技術支持。
- 邊緣數據處理: 物聯(lián)網、車聯(lián)網和工業(yè)互聯(lián)網的蓬勃發(fā)展,推動數據處理向邊緣側延伸。輕量化的邊緣數據庫、流處理框架和存儲方案,能夠在靠近數據源的位置完成初步的過濾、聚合和分析,減少云端傳輸壓力,滿足低延遲和離線可用的業(yè)務需求。
- 統(tǒng)一數據目錄與數據發(fā)現(xiàn): 隨著數據資產規(guī)模膨脹,快速發(fā)現(xiàn)、理解和使用可信數據成為痛點。統(tǒng)一數據目錄(Data Catalog)作為企業(yè)的數據“地圖”,通過自動化的元數據采集、數據血緣追蹤、數據質量監(jiān)控和業(yè)務術語關聯(lián),提升了數據的可發(fā)現(xiàn)性、可理解性和可信度,是發(fā)揮數據價值的前提。
- 可持續(xù)發(fā)展與綠色存儲: “雙碳”目標下,數據中心的能耗問題受到高度重視。數據處理與存儲服務商通過采用更高效的硬件(如QLC SSD、高密度磁盤)、優(yōu)化數據壓縮與編碼算法、實施智能分層存儲(將冷數據自動遷移至能耗更低的介質)以及提升數據中心PUE值等措施,推動大數據產業(yè)向更環(huán)保、可持續(xù)的方向發(fā)展。
2023年大數據領域的關鍵詞清晰地指向了 “融合、智能、實時、云原生與可信” 五大核心趨勢。數據處理與存儲支持服務不再僅僅是后臺支撐,而是直接賦能業(yè)務創(chuàng)新、驅動智能決策的戰(zhàn)略性資產。企業(yè)需要根據自身數據規(guī)模、業(yè)務場景和技術棧,靈活采納和組合這些關鍵技術,構建敏捷、高效、安全且成本優(yōu)化的新一代數據基礎設施。